RCU经典文献
- What is RCU, Fundamentally?
- What is RCU? Part 2: Usage
- RCU part 3: the RCU API
- linux kernel
- RCU作者的主页介绍
这几个连接简直就是一个宝藏,里面的干活很多很多!!!有时间一定要多看看。下文中的内容是看第一个和第二个链接的笔记和整理。直接观看原文,效果更佳。
![]()
RCU锁特点介绍
Read-copy_update(简称RCU)技术是一种数据同步机制。常见的数据同步机制有:互斥锁,自旋锁,读写锁,顺序锁,信号量等手段。而RCU锁是一种比较高效的并发编程技术,它与2002年10月被添加到Linux内核中,在很多场景中它是用来替代读写锁的。
RCU锁的特点有:
- 允许读写同时进行
- 任意读;写操作时先拷贝一个副本,在副本上进行修改、发布,并在合适时间释放原来的旧数据
- 读端不存在睡眠、阻塞、轮询,不会形成死锁,相比读写锁效率更高。
RCU也有自己的缺点:
- 低优先级的读操作可阻塞高优先级的写操作
- 宽限期可能比较长
这是由于RCU 写操作完毕后,会等待读端的完毕,等所有的读操作完毕后,宽限期结束,此时写端才会将资源释放。这里没有区分优先级,因此低优先级的读操作可能会影响到高优先级的写操作。
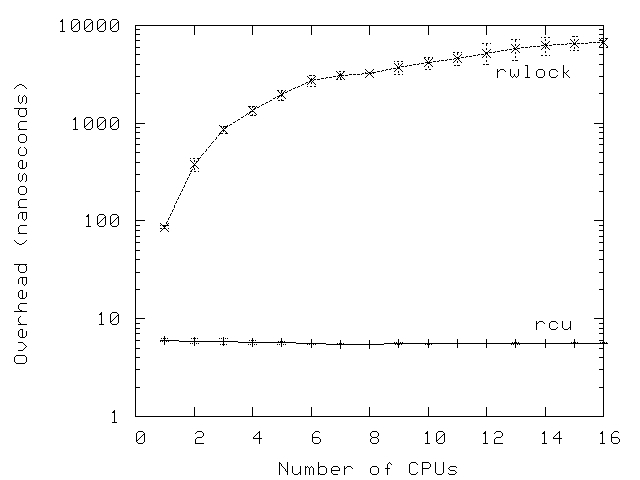
其实,RCU技术的特点还不仅如此,而有一个更重要的特点:多核扩展性。RCU虽然我们将其称之为RCU锁,但它并没有采用锁技术,而读写锁则是一个真正的锁,在扩展性上很差,设备CPU核越多,锁的竞争会越激烈,效率会越低。因此在现在很多的实现中,越来越注重无锁技术的实现。 下图是在文章What is RCU? Part 2: Usage中的一张RCU和rwlock在多核扩展性上对比图片:
RCU中常见问题
1. 有没有使用引用计数
关于RCU实现原理还有一个误解:RCU采用了引用计数的方式确定是否存在读者。 这个观点也是错的。首先RCU并没有采用引用计数的机制,而是采用了一种非常简单的技术来实现;其次如果非要深究到底有没有引用计数,按照What is RCU? Part 2: Usage中的说法是“RCU is a Restricted Reference-Counting Mechanism”,但本质上是没有采用引用计数的机制。它的解释如下:
“rcu_read_lock() 语句可以被认为是获取对 p 的引用,相当于一个引用计数。因为在 rcu_dereference() 分配给 p 之后开始的宽限期不可能在我们到达匹配的 rcu_read_unlock() 之前结束。 这种引用计数方案受到限制,因为我们不允许在 RCU 读端临界区中阻塞,也不允许我们将 RCU 读端临界区从一个任务切换到另一个任务“。 虽然有点像引用计数,但绝对不是。

至于它怎么实现:检测是否有人在引用当前变量呢? 我在下面介绍下
2. RCU既然没有使用引用计数,那又是确定是否存在读者引用之?
RCU 读锁加锁和去锁最基本的函数是:
1 |
加锁实际上是禁止上下文切换;而解锁是允许上下文切换。它们是一个全局设置,不与任何一项锁绑定。这也是为啥RCU读锁不需要任何参数的原因。
基于此,便可以通过让CPU进行一次上下文切换来实现检测读端是否完成,而不必跟踪每一个引用的进程。 这是一个RCU非常重要的特点.
进行这个操作是:synchronize_rcu(), 这个函数在内核中实现有点复杂,它毕竟还需要考虑中断,热插拔等因素。如果只考虑RCU部分,它的功能可以概括为:

第一个函数用来遍历所有的CPU;第二行run_on()函数用来将当前线程切换到指定的CPU上。如果这个任务顺利完成,则说明所有的核已经经历过一次上下文切换,此刻必定读端已经结束,否则无法触发切换。
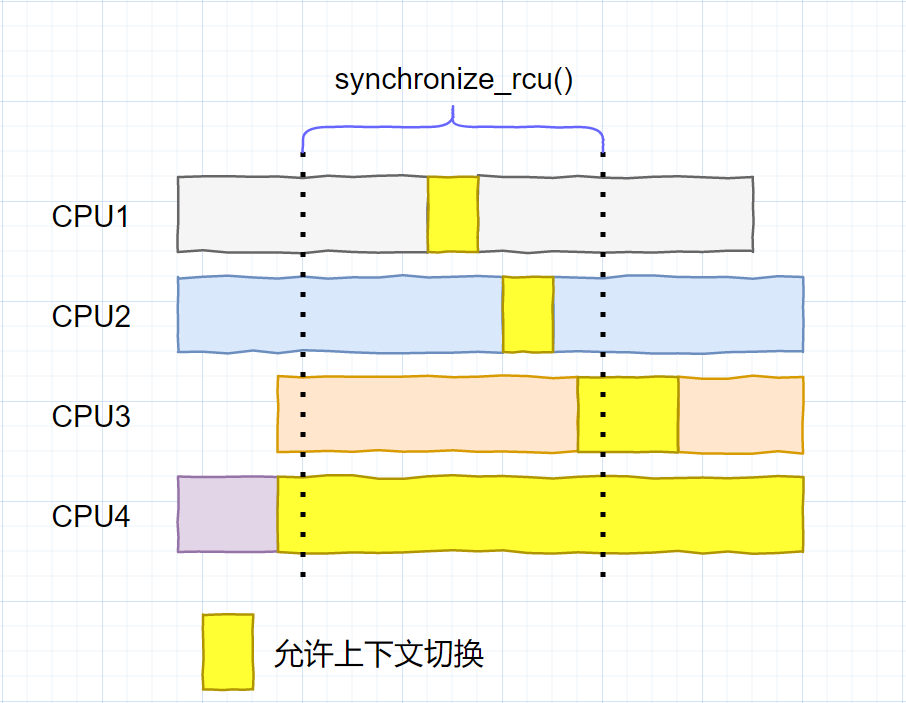
关于这里,我曾经有一个疑问:假如最初CPU1读端结束,执行了一次上下文切换;然后在等待其他CPU过程中,又再次进入RCU读临界区,如果此时释放,会导致严重后果吗? 有点类似于下图(黄色部分表示可以进行上下文切换)
不过后来想明白了。以替换一个节点为例进行说明:
- 链表最初状态如下:

插入一个元素时,先复制一个副本,再次基础上修改,然后完成发布
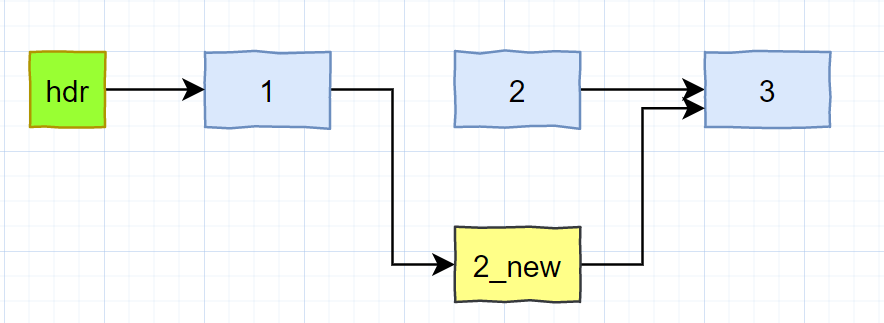
从此刻开始,rcu宽限期也开始。在发布之前的RCU读端访问的是2号节点(如果有的话),发布之后,新来的RCU读端读取的是2_new新节点。这是RCU的一个重要特点,实时性很好。
这里还没有完,旧的2号节点还没有被释放。
更新操作(资源回收)
那么什么时候释放呢? 当然是所有使用2号节点的读端都完成了再释放。
那么什么时候所有的读端完成呢?就是刚才提到的,**synchronize_rcu()函数的任务**。此函数返回后我们就可以释放了(异步释放也差不多,只不过通过回调函数来完成此项操作)
再回到刚才的问题:如果CPU都已经完成了一次上下文切换,准备进行资源释放时(例如将上面的2节点释放),其他CPU又重新进入临界区怎么办?
答案是:再次进入临界区的读端获取的是新的节点2_new, 原来的节点2已经不能再被新的读者访问到了。
这种检查原理上简单了很多,但也导致了rcu宽限期比较长。毕竟这个上下文切换是个全局设置,得照顾到所有的CPU。
3. RCU 读端和写端同时操作,不会触发段错误吗?
这个问题也是我当初百思不得其解的地方。
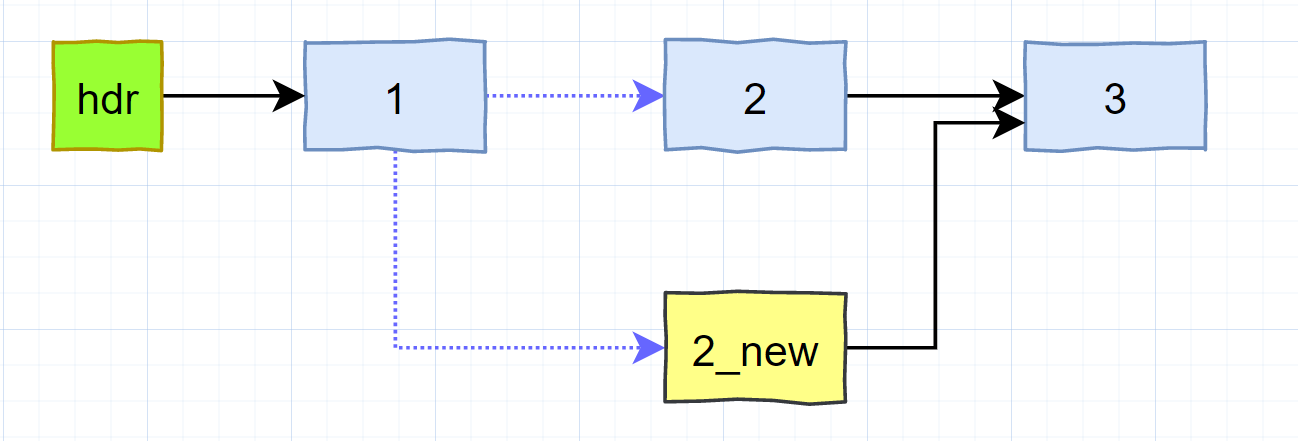
场景:
- 读端已经进入到1号节点
- 写端已经复制了2号节点2_new,完成了数据更新,并且将2_new的后继指针指向了3号节点
- 写端开始修改1号节点的后继指针,从2号节点切换到2_new节点;但是读端也正好在1号节点的后继节点,此时会出现后继节点为空导致链表遍历提前结束的情况吗?
这个问题困扰了很久。不过当我再次读What is RCU, Fundamentally?时,发现了上面有这个问题的回答。最初看时竟然没有注意到这个问题。

简单的说:在Linux系统中,所有的加载和存储操都是原子的,不可能被分割。针对上述场景,读端要么读取到2节点,要么读取到2_new节点。不会出现第三结果。
4. RCU 与资源回收

最初怎么也不会将这两个联系起来。但是慢慢发现有那么一丁点像
RCU会等待资源不再被引用时释放对应的资源。从这么一点看还确实有点像GC的赶脚
不过他们最大的区别在于(从资源回收上看):程序员必须手动指定RCU读端临界区资源,甚至手动指定释放的位置。